



Попри стрімкий розвиток штучного інтелекту, виявлено сферу, з якою нейромережі досі не справляються — це зчитування часу зі звичайних стрілочних годинників. У тесті ClockBench сучасні мовні моделі продемонстрували вкрай низьку точність, показавши результати, які суттєво відстають від людських можливостей.
ClockBench: тест на «аналогову грамотність» для ШІ
ClockBench — спеціалізований бенчмарк, створений для оцінки здатності моделей штучного інтелекту розпізнавати час за аналоговими циферблатами. Тест охоплює різні типи годинників, кути нахилу, варіанти оформлення та навіть частково закриті елементи циферблата.
Результати: розрив між людьми та ШІ
У дослідженні взяли участь кілька провідних мовних моделей:
- Gemini 2.5 Pro (від Google): лише 13,3% правильних відповідей;
- Моделі OpenAI (GPT-4, GPT-3.5): не перевищили 8,4% точності;
- Середній результат людини: 89%.
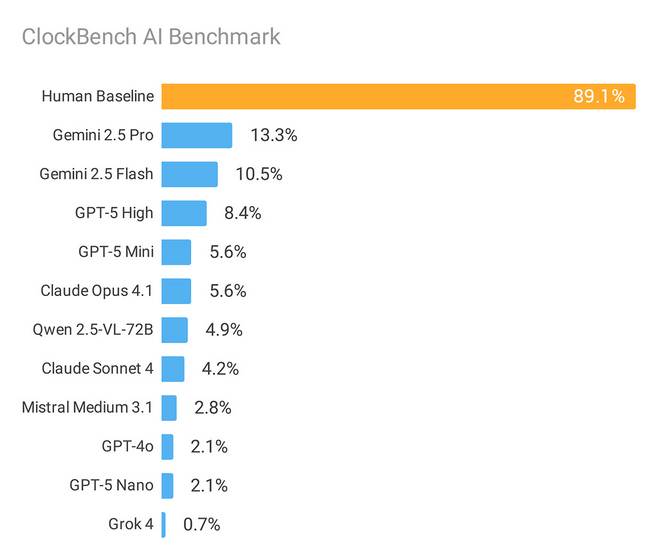
Різниця в точності становить майже 10-кратне відставання ШІ від людських користувачів. Це свідчить про те, що сучасні мовні моделі мають суттєві труднощі з базовими візуальними завданнями, які не викликають проблем у людей.




